RoY Week 2: Watson says my general concept is “F*ck”
- Gabriella Garcia

- Feb 10, 2019
- 5 min read
I wasn’t sure where to start with this week’s assignment, so like any sane person just starting to cut their programming teeth, I tried to teach myself basic ml4a machine learning in hopes of using it to execute some image-to-text analysis of my Instagram data, which I had acquired earlier in the week. The hope was to get a fairly accurate text translations of the photos I take and then analyze that text in a different format for potential insight.
I approached the task through Gene Kogan’s Machine Learning for Artists repository, which is an *excellent* resource with full lectures, slides, and examples from the class he taught last semester at ITP. I spent the better part of my Friday trying to follow along with his reverse image search guide, but found myself at the mercy of major roadblocks as he uses Python through Jupyter Notebooks, both of which were just introduced to me this week in Allison’s Reading and Writing E-Text class. I wasn’t able to parse through (let alone use) all of the technicals, I’m just not there yet, but the attempt was useful nonetheless as I now have a better grasp of the groundwork I’ll need to lay if I want to continue in the machine learning direction. I also got a great fundamental overview of Python and Jupyter Notebooks, which is absolutely practical studying for RWET.
A Deus ex (et cum) Machina
[forgive me Latin scholars] I’m continually validated that all time spent on the floor is proportionally rewarded. A classmate of mine noticed my exasperation and offered quite the solution (sort of); he had helped build a program that is intended to “mainstream” ml image analysis and let me run my images through his beta (currently still in stealth, so no names). The results were… less than stellar? A few examples below, captions are the result of the image-to-text analysis:



There are 687 images analyzed—the network obviously has a wide vocabulary, but works within a pretty narrow scope of generalizations/abstractions. I was however unsurprised to find that the program was quite adept at identifying cats, even when they are blurry (which I think they usually are?).

I scrolled through a length of analyses that included the word “cat” and they were always either correctly a cat, or the network trying to make a cat out of something that was not a cat. I sometimes consider the theory that toxoplasmosis (a neurologically-altering parasitespread by cats) has hit epidemic levels and maybe it’s jumped to the machine de facto our shaping the machine while infected hosts?
Anyway, the exercise said more about the machine than it did about me. I started to dig into some of the more beginner-friendly examples on ml5.js, but thought that the risk of hitting a similarly narrow scope of interpretation was too high for the time I’d end up spending figuring out how to make a dataset out of nearly 1000 images and building the code (this is a much longer project for me, and one I’d consider taking on).
Moving forward, I thought I could possibly reap more using the text I had actually written on Instagram, in the form of image and story captions.
Word count, Watson
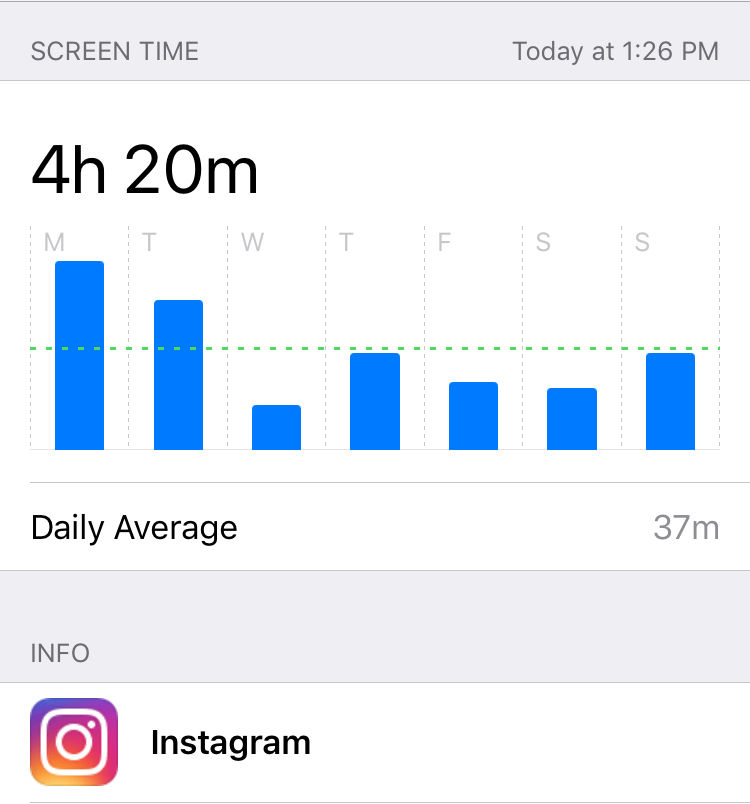
I was trying to figure out how to describe my “level” of Instagram use (medium-well engagement generally for amusement?) but the hard numbers are there… this past week I averaged 37 minutes a day, or 4 hours and twenty minutes over the course of the week. I thought it’d be worse.
I go between taking great care of what I write in my captions to being purposefully absurd, it’s hard for me to take Instagram seriously despite knowing that it’s also a Terrifying Data Monolith on which millions of entities depend. In any case, I figured the text I chose to write would have to say more than text from a sub-literate image analysis, as my text is a result of my creative consciousness regardless of how irrelevant I may consider it. Here are some screenshots of my text scraped by Instagram for my data request:



….out of context it looks a little crazy. The captions serve much better when paired with image. Seeing it all in one place displays an incredibly abstract use of language, and the sampling above is a sliver of what amounts to 7,438 words describing my visual perspective in one way or another. I used Shiffman’s Concordance word counter just to get the gist of what I’d be working with here… it turns out that the instances of words used only once more than doubles the instances of all words used at least twice (or 203 times in the case of the word “the”) combined, at 1819 of the former versus 827 of the latter. Given the stretches it could take to find patterns among unique words, I thought it would be fun to test a sentiment analysis on the full text scrape, which can bridge more abstract connections.
I decided to use IBM’s Natural Language Understanding demo, which is certainly not the most accurate way to measure sentiment but an accessible one that could at least whet the appetite for the technology. I also feel like I have this lifelong reverence for Watson that I now get to implicate myself in even on such a basic level as a NLP demo.
My overall emotion reads at Joy and Sadness competing for most detectable, while Anger, Disgust, and Fear race toward the bottom and nearly off the scale of significance. I’d say it’s a fairly accurate assessment of my curated presentation of self, but my self-in-the-world experiences certain and perceptible amounts of fear and anger.

Far more entertaining however is Watson’s identification of a general concept “that may not be directly referenced in the text.”
My general concept is “F*ck”
Yup. That’s what Watson thinks. In researching further as to what this means, IBM explains concept analysis as returning “high-level concepts in the content. For example, a research paper about deep learning might return the concept, “Artificial Intelligence” although the term is not mentioned.” It’s essentially an interpretation the of the implicit semantic information of a given body of text, not necessarily spelled out, but the basic “gist” of the content so to speak. My “gist” happens to be “F*ck.” I’m sorry I keep saying that, I’m just mesmerized.

It’s moving, really, that Watson would give me this substantial-yet-pliable word to ponder. I pretty much thought the same thing when I looked at all my text scraped together. The explicative is such a conceptual multiplex in its own right that I can almost read the interpretation as an intuitive cop-out on the level of astrology? Should I read it as explicit, or exclamatory, or lost? Is this the “gist” my expression gives forth to the world? Pliable but substantial?
I have so much more to say, including thoughts on The Meme Machine though I’m only about 25% of the way through. I find Dr. Blackmore’s arguments actually quite comforting, that replicators are seeds waiting to fertilize the soil of our mind, imagine what gardens one can cultivate? I’ll come back for a more thorough response on that one.



Comments